Are you ready to revolutionize the way we power our communities and data centers? Picture a future where electricity isn't just distributed from centralized grids but generated and managed locally. Welcome to the world of microgrids, battery energy storage systems, and electronic isolation and controls.
While it is fun to use these buzzwords and speak about the possibilities the future holds, why does this matter? Simply put, resources. Whether it is capital, space, power, water, or talent, we live in a resource constrained world. As our technology becomes more advanced, its demands for power and cooling will increase. This puts a large strain on our already fully loaded power grids, with the states ¹most at-risk being Texas, Michigan, Ohio, New York, and California. Texas is not interconnected to the national grid, which puts it at risk for downtime due to a lack of redundancy. New York and California, on the other hand, are strained due to their large populations and the decommissioning of traditional power plants. Additionally, with an increase in legislation supporting EV vehicles, the strain on the grid can be too large especially in inclement weather (i.e. hot and cold) increasing risk of downtime.
Like it or not, soon we will have to supplement power and storage solutions that are smart and reliable enough to be treated as de-centralized grid assets. Let us dive deeper into the realm of Microgrids.
What is a microgrid?
Microgrids represent a paradigm shift in how we think about energy distribution. These localized grids can operate independently or in conjunction with the main grid, offering resilience and flexibility in the face of outages and disruptions.
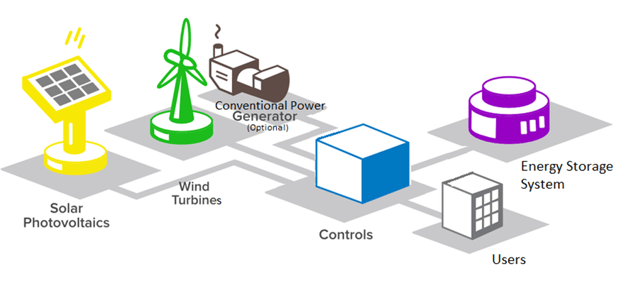 So, what are some of the basic components that we’d expect to see in a microgrid? Renewable energy, most commonly solar (PV), wind, or, in some cases, hydropower. Next, we would expect to see an inverter to convert the energy from the renewables to a usable form for the loads that are connected. After that, a BESS (Battery Energy Storage System), isolation with controls, a fuel cell, and/or hydrogen electrolyzer.
So, what are some of the basic components that we’d expect to see in a microgrid? Renewable energy, most commonly solar (PV), wind, or, in some cases, hydropower. Next, we would expect to see an inverter to convert the energy from the renewables to a usable form for the loads that are connected. After that, a BESS (Battery Energy Storage System), isolation with controls, a fuel cell, and/or hydrogen electrolyzer.
While these individual components, alone, could not support an outage, when deployed together, the sky is the limit for “islanding” yourself from utility. These assets could be on a commercial site, outside of a housing community, a data center, and beyond. These are the building blocks for these locally deployed decentralized grids.
Imagine a community powered by its own microgrid, seamlessly integrating renewable energy sources, like solar panels and battery storage systems, into its infrastructure. These technologies not only reduce reliance on fossil fuels but also pave the way for a more sustainable future.
Outside of the communities, integrating renewables into their energy portfolio, there are mission critical operators who look to add redundancy to their utility connection and further control their uptime parameters. Mission critical operations are businesses that cannot suffer an outage even for a second. These customers are mostly data centers, healthcare providers, departments of transportation, utilities, etc.
Furthering the point of living in a resource-constrained environment, these providers are seeing that the addition of high compute applications are driving their energy consumption up higher every year. To combat the risk associated with simply relying on utility, they deploy uninterruptible power supplies, generators, and, now, renewables and BESS systems to allow them even more flexibility during utility loss.
Market Overview
As AI and other high performance compute practices start becoming the norm in the market, the utilities won’t be able to adapt quick enough. Standard per rack power density in hyperscale and co-location data centers ranges from 10 - 20 kW of consumption. And, in the next 3-5 years, market analysis predicts for this to shoot to 50 - 300 kW/rack of consumption. While this can increase revenue per sq/ft tremendously in colocation data halls, it is also introducing challenges in cooling and power requirements. Liquid cooling, active rear door heat exchangers, and cold plates, are poised to address these challenges on the heat rejection side. However, the power requirements are an entirely different beast to deal with.
 Enter, the need to BYOP (Bring Your Own Power). This is a facility level strategy that is creating and managing your own distribution, generation, and energy asset deployment. This can be accomplished through a variety of solutions. Utilizing DERs (Distributed Energy Resources), which is a fancy terminology to describe the energy generating and storage assets that comprise a microgrid, facilities can manage peak demand, add layers of redundancy to their systems, and ultimately, completely island themselves from the grid.
Enter, the need to BYOP (Bring Your Own Power). This is a facility level strategy that is creating and managing your own distribution, generation, and energy asset deployment. This can be accomplished through a variety of solutions. Utilizing DERs (Distributed Energy Resources), which is a fancy terminology to describe the energy generating and storage assets that comprise a microgrid, facilities can manage peak demand, add layers of redundancy to their systems, and ultimately, completely island themselves from the grid.
While a completely renewable and stand-alone data center is not happening in the next 1-2 years, it is just over the horizon, and it is critical to start having important conversations as these systems require large intellectual investment, planning, and capital to get them off the drawing boards and into the real world.
While the matters mentioned above mainly concern data center providers, an energy intensive activity that more and more consumers are participating in, every day, is… Electric Vehicle (EV) charging. Subsequently, never have we seen before, parking garages and multifamily home developments requiring the addition of new transformers to support 1000 amp and above services. Super chargers and 220V standard EV chargers require a large amount of power to charge vehicles quickly. Understandably, this strains the utility provider, especially considering that most charging is occurring simultaneously. What this looks like is a large group of EV users who commute to work and charge during the day, and another other group of users who charge exclusively at home during the night. As adoption increases, these routinely popular charging times become more and more problematic for utility providers.
So, as the US continues to push automakers to electrify their fleets, the demand on the grid and surrounding infrastructures cannot keep up. Critical equipment necessary to install these new services have lead times measured in years, while the cost to retrofit existing parking structures to support charging can add up quickly, pricing many providers out of the market.

The need for more readily available power is here, and we are just barely knocking on the door of what is possible, as we will need to, as an adapted society, further expand upon the utilization of already existing technologies. And, as mentioned, a BESS and PV Farm separately will not achieve much, but the value lies in linking them together into a smart controllable system. As we continue to be creative with implementing these already existing solutions together, then we can iterate and create more efficient systems, which allows for more of a mainstream adoption across the industry.
Looking Ahead
Plain and simple, for most operations these solutions are currently cost prohibitive. However, let’s keep in mind a key learning from the ramp up of the solar industry; Utilities and governments are willing to subsidize and incentivize companies that choose to implement these solutions ahead of the curve. Currently, in Utah, Rocky Mountain Power (RMP) is rolling out an incentive program that is either per kWh or a one-time upfront incentive for the installation of a BESS. These are not small sums either, with some programs covering up to 75% of the cost of the BESS.
One may ask, what is the angle for RMP? In short, the more DERs that are connected to the grid, the more redundancy is built into the utility framework. In the case of a contingency, these assets can all be controlled as one, spinning reserve for RMP. During normal operation, owners can enjoy peak shaving benefits, as well as outage protection. A truly rare “win-win” scenario. As peak demand charges continue to increase, ROI numbers start to make sense on 12- and 24-month timelines.
Additionally, RMP is utilizing “Make-Ready” incentives to support the adoption and installation of EV charging. These incentives could cover up to 100% of the cost associated with powering EV chargers in commercial and residential applications.
To further this discussion of the future, we can start to think of abstract solutions such as on-site hydrogen generation using natural gas. We can replace diesel gensets with hydrogen fuel cells, as hydrogen is three-times more energy dense/liter than diesel. We are even close to the deployment of small, self-contained, 300 – 500 MW nuclear reactors that can be deployed in remote environments and do not require service for 60 years.
So, when it comes to reliability and cost savings, all signs point to BYOP.
While the adoption of microgrid solutions may currently pose financial challenges, the tide is turning as incentives and awareness grow. Just as the solar industry witnessed exponential growth fueled by supportive policies, the trajectory of microgrids and BESS suggests a similar transformation in the energy landscape. As we stand on the cusp of this paradigm shift, it is necessary to initiate conversations and investments today for a more sustainable and resilient tomorrow. The journey towards decentralized, renewable energy is not merely an option; it's a strategic imperative for businesses and communities alike.
If you enjoyed this high-level overview of the current market of microgrids, please join us for part two of this blog series, which will be released the last week of March. We'll do a deep dive on use/case and applications, and we’ll expand upon DVL’s current product offerings that support this infrastructure and qualify for utility incentives. Additionally, we will provide real-life applications to this equipment.
Have a question or comment about this blog?
Reach out to blog author Alexander "D'Angelo" D'Angelo, Power Systems Sales Engineer, (based out of our Salt Lake City office) at ADangelo@DVLnet.com.
¹ https://www.generac.com/be-prepared/power-outages/top-5-states-where-power-outage-occur